SmartChart数据集可以使用Pandas来做数据处理,完全兼容Pandas语法
ds变量名是最终的数据集, 你需要产出它即可
内置函数
#读取数据集
ds_df(id,para_dict=None,cachestr=None,columns=None)
df=ds_df(359) #获取ID为359这个数据集的数据并转化为pandas的dataframe(df)
df=mysmart.pddf(359,columns=['C1','C2','D1']) #可指定标题名称
#读取excel
import pandas as pd
df = pd.read_excel('path_to_file.xls', sheet_name='Sheet1')
#产出ds
ds = ds_list(df)

以下仅说明SmartChart常用方法,更多可在Pandas API中查询
合并数据集(相当于SQL的union all)
result = pd.concat([df1,df2,df3])
result = df1.append([df2,df3])

关联数据集(相当于SQL的join, EXCEL的vlookup)
result = pd.merge(left,right,how='left',on=['key1','key2'])

数据分组(相当SQL的groupby)
以下C1, C2 ... 指维度, D1, D2, D3 指数据列
#按C1,C2对数据分总
grouped = df.groupby(['C1','C2'])
#其它数据加总
#正常Pandas聚合后的列变成index, 所以最终你要reset_index()
df = grouped.sum().reset_index()
#不过smartchart应用为了简便,对Pandas源码进行了修改,
#groupby,pivot,pivot_table的操作会自动重置, 不需再加
#按对D1做3种聚合方式, 再重命名结果
df = grouped['D1'].agg([np.sum, np.mean, np.std]).rename(columns={'sum': 'foo','mean': 'bar','std': 'baz'})
#对不同列使用不同聚合方式
df = grouped.agg({'D1': 'sum', 'D2': 'std'})
#获取一个分组的数据
df = grouped.get_group(2014)
下面案例详细group过程
#将数据按company进行分组
df.groupby("company")
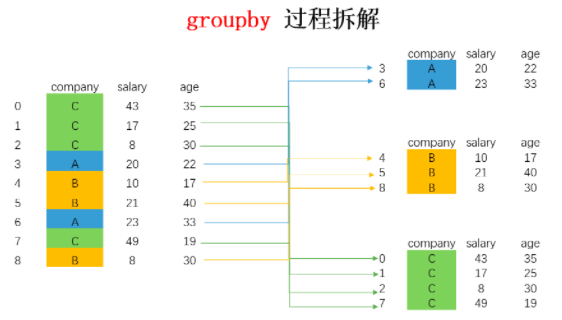
#将数据按company进行分组并对salary和age用不同方法统计
df.groupby('company').agg({'salary':'median','age':'mean'})

#新增一列avg_salary, 使用分组计算的salary的中间填充
df['avg_salary'] = df.groupby('company')['salary'].transform('mean')
![]()
数据透视
#对原始数据进行透视表(并做聚合)处理, #fill_value填充空值,margins=True进行汇总
#可选columns=['C3'], 一般smartchart图形不用
df = pd.pivot_table(df,index=['C1','C2'],values=['D1','D2','D3'],aggfunc=[np.sum,np.mean],fill_value=0)
pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'], aggfunc=np.sum, fill_value=0)
#对原始数据进行透视,不会聚合
df = df.pivot(index='C1', columns='C2')['D1']

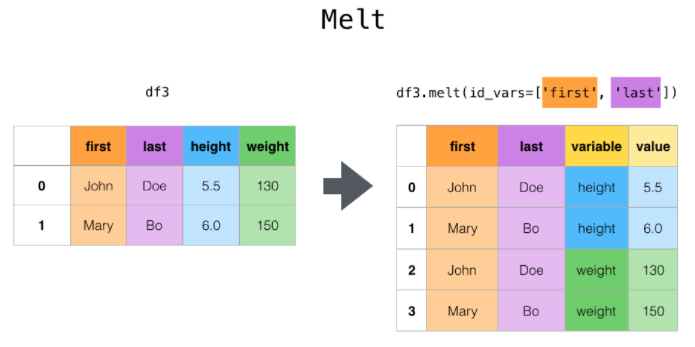
逆透视
df.melt(id_vars=['first', 'last'], var_name='quantity')
选择数据
#选取列名为A的列 df.A 或者 df['A']
#切片选择[0:3]行 df[0:3]
#所有的行都保留,筛选出 'A','B'这两列的数据
df.loc[:, ['A', 'B']]
#选择第三行 df.iloc[3])
#第三行的第一位 df.iloc[3, 1]
#切片选择 3:5行 1:3列
df.iloc[3:5, 1:3]
#不连续筛选
df.iloc[[1, 3, 5], 1:3]
#选择最后一行,A,B列
df.iloc[-1,['A','B']]
筛选
#找出df中A列值为100的所有数据
df[df.A==100]
#找出df中A列值为100、200、300的所有数据
num = [100, 200, 300]
df[df.A.isin(num)]
#找出df中A列值为100且B列值为‘a’的所有数据
df[(df.A==100)&(df.B=='a')]
#找出df中A列值为100或B列值为‘a’的所有数据
df[(df.A==100)|(df.B=='b')]
#排序
df.sort_values(['A','B'], ascending=False)
列名(标题)操作
#重排顺序
order = ['date', 'time', 'open', 'high', 'low', 'close']
df = df[order]
#重命名
df.columns=['A','B','C']
#替换名称
df.rename({"CALMONTH":"month"}, axis='columns', inplace=True)
#移动列
s = df.pop('source') #弹出source列
df.insert(0,'source',s) #将source插入到第一列
Pandas与SmartChart
'''
Pandas数据集更多的建议是用于公用数据集, 因为如果用到同一个数据源
不应该多次读取处理, 而是可以在一个数据集中处理完成
我们可以通将df返回为字典的格式进行传递
'''
df1 = xxxx #处理完的第一个df
df2 = xxxxx #处理完的第二个df
df = {"df1":df1, "df2":df2}
#那么其它数据集如何引用Pandas这个公用数据集
#参考dashboard的高级设定-公用数据集, 这样引用:
{
"commonds":{
"4":"data0['df1']", //df1分配给2号图形
"5":"data0['df2']" //df2分配给5号图形
}
}
Sample
df1 = pddf(21) #获取数据集ID为21的数据
df2 = pddf(22) #获取数据集ID为22的数据
df1.rename({"CALMONTH":"month"}, axis='columns', inplace=True) #修改BW的标头名称
df = pd.concat([df1,df2],keys=['bw','impala']).reset_index() #合并BW和impala的数据,并用key进行标识key移到数据
df.fillna(0, inplace=True) #NA的数据补0
df = df.drop(['month','level_1'],axis=1).rename({"level_0":"source"},axis=1) #移除月份等多余的列并重命名列
s = df.iloc[:,1:].apply(lambda col: col[0] - col[1], axis=0) #对数据列上下行相减得到新的系列
df = df.append(s,ignore_index=True) #追加系列到最后一行
df.loc[2,'source'] = 'delta' #将最后一行的source列改变值
df.iloc[-1,1:] = df.iloc[-1,1:].apply(lambda x: int(x)) #将最后一行数据取整
df1['source']='bw'
df2['source']='impala'
df = pd.concat([df1,df2]).reset_index() --合并后index需重新排序后会多出一列原来的index
s = df.pop('source') --弹出source列
df = df.drop(columns=['month','index']) --移除月份,合并前的index
df.insert(0,'source',s) --将source插入到第一列
df = tmpDF.groupby('客诉等级').sum().reset_index() #分类汇总
df = tmpDF.loc[:,['客诉等级','工单数量']] #获取tmpDF指定列并赋值给df
df.T #转置
df['B'] = df['B'].map(lambda x: x+1) #用于series中的每一个元素进行函数操作
df = df.applymap('{:.2f}'.format);#用于对dataframe中的每一个元素进行操作
df = df.apply(lambda x: x.sum) #用于对dataframe中行或列进行操作
df.rename({"A":"B"}, axis='columns', inplace=True) # 修改名字 inplace=True 代表修改当前df,修改列的名字从A 到 B
df.fillna(0, inplace=True) # 将df的nan用0代替
df['B'].unique()
df.head() #默认前10行数据
df.tail() #默认后10 行数据
df['price'].fillna(df['price'].mean()).tail(n=3)
df['city'].drop_duplicates(keep='last')
df['city'].replace('sh', 'shanghai')
df_inner=pd.merge(df,df1,how='inner') # 匹配合并,交集
df_left=pd.merge(df,df1,how='left')
df_right=pd.merge(df,df1,how='right')
df_outer=pd.merge(df,df1,how='outer') #并集
result = df1.append(df2)
result = left.join(right, on='key')
df_inner.loc[3]
df_inner.iloc[0:5]
df_inner.loc[(df_inner['age'] > 25) |(df_inner['city'] == 'beijing'), ['id','city','age','category','gender']].sort(['id']).city.count()