SmartChart从V3.9.8.5 开始支持一键分享和应用模板
模板查询商店入口:
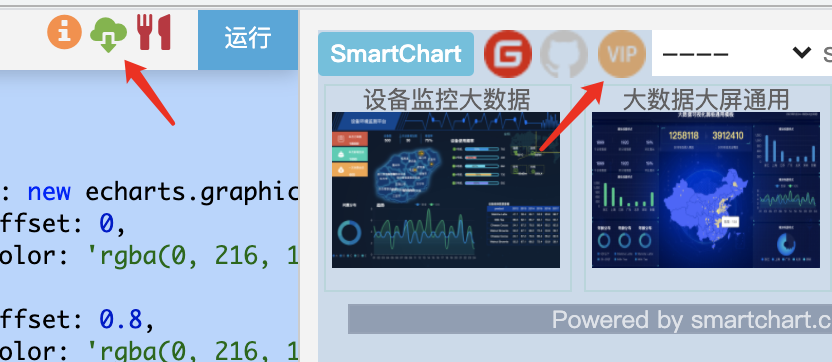
使用方法可参考视屏: 一键应用模板
如何获取模板应用权限
由于开发模板需要耗费一定的精力和服务器资源, 为了smartchart生态能稳定运行和鼓励大家开发模板, 所以一键应用模板的功能为有偿服务, 模板价格的查询如上图,模板查询, 赞赏完备注模板名,后加右方微信获取下载码 目前有偿服务有:
- 模板的云备份存储, 你要可以随时随地上传下载你自已的模板
- 一键应用炫酷的共享模板

请尊重知识产权, 获取模板后, 不要在散布
如何使用
模板开发人员可以向smartchart管理员申请一个模板KEY(用于上传


 > Big Data Ecosystem(仅供参考,不是最新的!!
> Big Data Ecosystem(仅供参考,不是最新的!!